
DP-100 Online Practice Questions and Answers
Questions 4
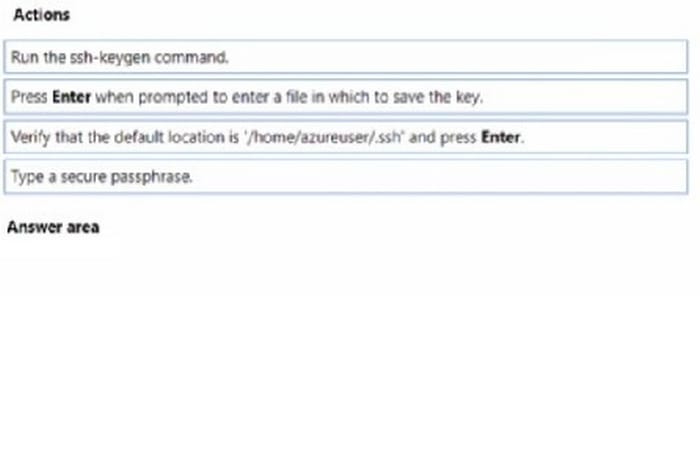
DRAG DROP
You need to implement source control for scripts in an Azure Machine Learning workspace. You use a terminal window in the Azure Machine Learning Notebook tab
You must authenticate your Git account with SSH.
You need to generate a new SSH key.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them m the correct order.
Select and Place:

Questions 5
HOTSPOT
You are a lead data scientist for a project that tracks the health and migration of birds. You create a multi-image classification deep learning model that uses a set of labeled bird photos collected by experts. You plan to use the model to
develop a cross-platform mobile app that predicts the species of bird captured by app users.
You must test and deploy the trained model as a web service. The deployed model must meet the following requirements:
1.
An authenticated connection must not be required for testing.
2.
The deployed model must perform with low latency during inferencing.
3.
The REST endpoints must be scalable and should have a capacity to handle large number of requests when multiple end users are using the mobile application.
You need to verify that the web service returns predictions in the expected JSON format when a valid REST request is submitted.
Which compute resources should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:


Questions 6
HOTSPOT
Complete the sentence by selecting the correct option in the answer area.
Hot Area:


Questions 7
You create a batch inference pipeline by using the Azure ML SDK. You run the pipeline by using the following code:
from azureml.pipeline.core import Pipeline
from azureml.core.experiment import Experiment
pipeline = Pipeline(workspace=ws, steps=[parallelrun_step]) pipeline_run = Experiment(ws, 'batch_pipeline').submit(pipeline)
You need to monitor the progress of the pipeline execution.
What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.

A. Option A
B. Option B
C. Option C
D. Option D
E. Option E
Questions 8
You plan to use a Data Science Virtual Machine (DSVM) with the open source deep learning frameworks Caffe2 and Theano. You need to select a pre configured DSVM to support the framework. Which of following should you create?
A. Data Science Virtual Machine for Linux (Ubuntu)
B. Data Science Virtual Machine for Windows 2012
C. Data Science Virtual Machine for Windows 2016
D. Data Science Virtual Machine for Linux (CentOS)
Questions 9
You have been tasked with ascertaining if two sets of data differ considerably. You will make use of Azure Machine Learning Studio to complete your task.
You plan to perform a paired t-test.
Which of the following are conditions that must apply to use a paired t-test? (Choose all that apply.)
A. All scores are independent from each other.
B. You have a matched pairs of scores.
C. The sampling distribution of d is normal.
D. The sampling distribution of x1- x2 is normal.
Questions 10
You are planning to make use of Azure Machine Learning designer to train models.
You need choose a suitable compute type.
Recommendation: You choose Attached compute.
Will the requirements be satisfied?
A. Yes
B. No
Questions 11
You are planning to make use of Azure Machine Learning designer to train models.
You need choose a suitable compute type.
Recommendation: You choose Inference cluster.
Will the requirements be satisfied?
A. Yes
B. No
Questions 12
You use the Azure Machine Learning designer to create and run a training pipeline.
The pipeline must be run every night to inference predictions from a large volume of files. The folder where the files will be stored is defined as a dataset.
You need to publish the pipeline as a REST service that can be used for the nightly inferencing run.
What should you do?
A. Create a batch inference pipeline
B. Set the compute target for the pipeline to an inference cluster
C. Create a real-time inference pipeline
D. Clone the pipeline
Questions 13
You create an Azure Machine Learning workspace. The workspace contains a dataset named sample.dataset, a compute instance, and a compute cluster. You must create a two-stage pipeline that will prepare data in the dataset and then train and register a model based on the prepared data. The first stage of the pipeline contains the following code:
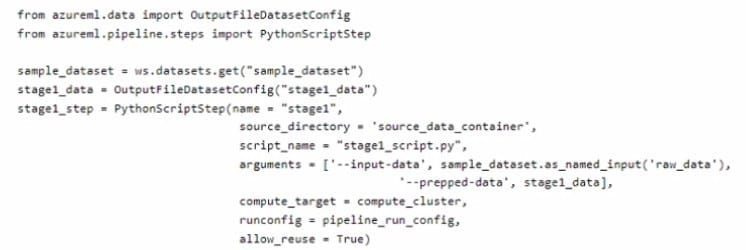
You need to identify the location containing the output of the first stage of the script that you can use as input for the second stage. Which storage location should you use?
A. workspaceblobstore datastore
B. workspacefi lest ore datastore
C. compute instance
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2026 pass2lead.com, All Rights Reserved.