
SPLK-3003 Online Practice Questions and Answers
Questions 4
A [script://] input sends data to a Splunk forwarder using which method?
A. UDP stream
B. TCP stream
C. Temporary file
D. STDOUT/STDERR
Questions 5
An index receives approximately 50GB of data per day per indexer at an even and consistent rate. The customer would like to keep this data searchable for a minimum of 30 days. In addition, they have hourly scheduled searches that process a week's worth of data and are quite sensitive to search performance.
Given ideal conditions (no restarts, nor drops/bursts in data volume), and following PS best practices, which of the following sets of indexes.conf settings can be leveraged to meet the requirements?
A. frozenTimePeriodInSecs, maxDataSize, maxVolumeDataSizeMB, maxHotBuckets
B. maxDataSize, maxTotalDataSizeMB, maxHotBuckets, maxGlobalDataSizeMB
C. maxDataSize, frozenTimePeriodInSecs, maxVolumeDataSizeMB
D. frozenTimePeriodInSecs, maxWarmDBCount, homePath.maxDataSizeMB, maxHotSpanSecs
Questions 6
A customer has a Universal Forwarder (UF) with an inputs.conf monitoring its splunkd.log. The data is sent through a heavy forwarder to an indexer. Where does the Index time parsing occur?
A. Indexer
B. Universal forwarder
C. Search head
D. Heavy forwarder
Questions 7
What is the default push mode for a search head cluster deployer app configuration bundle?
A. full
B. merge_to_default
C. default_only
D. local_only
Questions 8
A customer has a multisite cluster (two sites, each site in its own data center) and users experiencing a slow response when searches are run on search heads located in either site. The Search Job Inspector shows the delay is being caused by search heads on either site waiting for results to be returned by indexers on the opposing site. The network team has confirmed that there is limited bandwidth available between the two data centers, which are in different geographic locations.
Which of the following would be the least expensive and easiest way to improve search performance?
A. Configure site_search_factor to ensure a searchable copy exists in the local site for each search head.
B. Move all indexers and search heads in one of the data centers into the same site.
C. Install a network pipe with more bandwidth between the two data centers.
D. Set the site setting on each indexer in the server.conf clustering stanza to be the same for all indexers regardless of site.
Questions 9
In a large cloud customer environment with many (>100) dynamically created endpoint systems, each with a UF already deployed, what is the best approach for associating these systems with an appropriate serverclass on the deployment server?
A. Work with the cloud orchestration team to create a common host-naming convention for these systems so a simple pattern can be used in the serverclass.conf whitelist attribute.
B. Create a CSV lookup file for each severclass, manually keep track of the endpoints within this CSV file, and leverage the whitelist.from_pathname attribute in serverclass.conf.
C. Work with the cloud orchestration team to dynamically insert an appropriate clientName setting into each endpoint's local/deploymentclient.conf which can be matched by whitelist in serverclass.conf.
D. Using an installation bootstrap script run a CLI command to assign a clientName setting and permit serverclass.conf whitelist simplification.
Questions 10
Which of the following is the most efficient search?
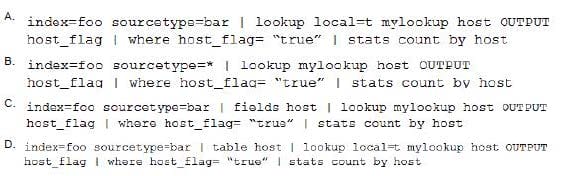
A. Option A
B. Option B
C. Option C
D. Option D
Questions 11
A customer would like to remove the output_file capability from users with the default user role to stop them from filling up the disk on the search head with lookup files. What is the best way to remove this capability from users?
A. Create a new role without the output_file capability that inherits the default user role and assign it to the users.
B. Create a new role with the output_file capability that inherits the default user role and assign it to the users.
C. Edit the default user role and remove the output_file capability.
D. Clone the default user role, remove the output_file capability, and assign it to the users.
Questions 12
In an environment that has Indexer Clustering, the Monitoring Console (MC) provides dashboards to monitor environment health. As the environment grows over time and new indexers are added, which steps would ensure the MC is aware of the additional indexers?
A. No changes are necessary, the Monitoring Console has self-configuration capabilities.
B. Using the MC setup UI, review and apply the changes.
C. Remove and re-add the cluster master from the indexer clustering UI page to add new peers, then apply the changes under the MC setup UI.
D. Each new indexer needs to be added using the distributed search UI, then settings must be saved under the MC setup UI.
Questions 13
When monitoring and forwarding events collected from a file containing unstructured textual events, what is the difference in the Splunk2Splunk payload traffic sent between a universal forwarder (UF) and indexer compared to the Splunk2Splunk payload sent between a heavy forwarder (HF) and the indexer layer? (Assume that the file is being monitored locally on the forwarder.)
A. The payload format sent from the UF versus the HF is exactly the same. The payload size is identical because they're both sending 64K chunks.
B. The UF sends a stream of data containing one set of medata fields to represent the entire stream, whereas the HF sends individual events, each with their own metadata fields attached, resulting in a lager payload.
C. The UF will generally send the payload in the same format, but only when the sourcetype is specified in the inputs.conf and EVENT_BREAKER_ENABLE is set to true.
D. The HF sends a stream of 64K TCP chunks with one set of metadata fields attached to represent the entire stream, whereas the UF sends individual events, each with their own metadata fields attached.
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2026 pass2lead.com, All Rights Reserved.