

 Printable PDF
Printable PDF

SAP Certified Associate - Back-End Developer - ABAP Cloud: C_ABAPD_2309
Want to pass your SAP Certified Associate - Back-End Developer - ABAP Cloud C_ABAPD_2309 exam in the very first attempt? Try Pass2lead! It is equally effective for both starters and IT professionals.
- Vendor: SAP
- Exam Code: C_ABAPD_2309
- Exam Name: SAP Certified Associate - Back-End Developer - ABAP Cloud
- Certifications: SAP Certifications
- Total Questions: 81 Q&As( View Details)
- Updated on: Oct 01, 2025
- Exam retired ,new exam code replace: C_ABAPD_2507




- Q&As Identical to the VCE Product
- Windows, Mac, Linux, Mobile Phone
- Printable PDF without Watermark
- Instant Download Access
- Download Free PDF Demo
- Includes 365 Days of Free Updates
VCE
- Q&As Identical to the PDF Product
- Windows Only
- Simulates a Real Exam Environment
- Review Test History and Performance
- Instant Download Access
- Includes 365 Days of Free Updates
Passing Certification Exams Made Easy
Everything you need prepare and quickly pass the tough certification exams the first time
- 99.5% pass rate
- 7 Years experience
- 7000+ IT Exam Q&As
- 70000+ satisfied customers
- 365 days Free Update
- 3 days of preparation before your test
- 100% Safe shopping experience
- 24/7 Support
Free C_ABAPD_2309 Exam Questions in PDF Format
Related SAP Certifications Exams
C_ABAPD_2309 Online Practice Questions and Answers
Questions 1
What would be the correct expression to change a given string value 'mr joe doe' into 'JOE' in an ABAP SQL field list?
A. SELECT FROM TABLE dbtabl FIELDS Of1, upper(left( 'mr joe doe', 6)) AS f2_up_left, f3,
B. SELECT FROM TABLE dbtabl FIELDS Of1, left(lower(substring( 'mr joe doe', 4, 3)), 3) AS f2_left_lo_sub, f3,
C. SELECT FROM TABLE dbtabl FIELDS Of1, substring(upper('mr joe doe'), 4, 3) AS f2_sub_up, f3,...
D. SELECT FROM TABLE dbtabl FIELDS Of1, substring(lower(upper( 'mr joe doe' ) ), 4, 3) AS f2_sub_lo_up, f3,
Questions 2
Which ABAP SQL clause allows the use of inline declarations?
A. FROM
B. INTO CORRESPONDING FIELDS OF
C. INTO
D. FIELDS
Questions 3
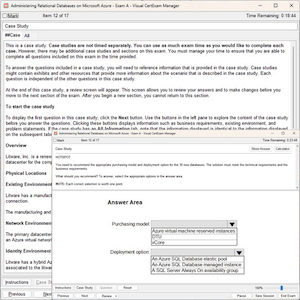
In which products must you use the ABAP Cloud Development Model? Note: There are 2 correct answers to this question.
A. SAP S/4HANA Cloud, private edition
B. SAP BTP, ABAP environment
C. SAP S/4HANA on premise
D. SAP S/4HANA Cloud, public edition
Reviews
-
zyz
 Indiathere are many same questions between this dumps and exam, so i have passed the exam this morning.thanks for this dumps
Indiathere are many same questions between this dumps and exam, so i have passed the exam this morning.thanks for this dumps -
Wanda
 RwandaDump still valid, I got 979/1000 today. Thanks to you all.
RwandaDump still valid, I got 979/1000 today. Thanks to you all. -
Sam
 MongoliaToday i passed the exam, This dumps is valid exactly. Please read all of theory and then use this dumps.
MongoliaToday i passed the exam, This dumps is valid exactly. Please read all of theory and then use this dumps. -
Quennell
 EgyptThe new questions in the exam are not the new questions for me because I have met them when I used this material . So there is no doubt that I have passed the exam with high score. Recommend this material strongly.
EgyptThe new questions in the exam are not the new questions for me because I have met them when I used this material . So there is no doubt that I have passed the exam with high score. Recommend this material strongly. -
Varner
 Germanyi'm an engineer and have not much time to prepare for the exam. Before two months, one of my friends intriduced this dumps to me. From then on, I only planned one hour to study this dumps and do the questions. Sometime i was so busy and had no time to do it. So before i begun my exam, I think I would fail the exam. But when i begun the exam, I found many same questions with the dumps, so i felt more and more confident and at last i passed the exam luckly. Thanks for this dumps and special to my friend.
Germanyi'm an engineer and have not much time to prepare for the exam. Before two months, one of my friends intriduced this dumps to me. From then on, I only planned one hour to study this dumps and do the questions. Sometime i was so busy and had no time to do it. So before i begun my exam, I think I would fail the exam. But when i begun the exam, I found many same questions with the dumps, so i felt more and more confident and at last i passed the exam luckly. Thanks for this dumps and special to my friend. -
Terrell
IndiaValid. Passed Today.....So happy, I will recommend it to my friends. -
Orlando
 BangladeshMany questions are from the dumps but few question changed. Need to be attention.
BangladeshMany questions are from the dumps but few question changed. Need to be attention. -
Teressa
 SingaporeWonderful dumps. I really appreciated this dumps with so many new questions and update so quickly. Recommend strongly.
SingaporeWonderful dumps. I really appreciated this dumps with so many new questions and update so quickly. Recommend strongly. -
Jo
Indiahi guys this dumps is enough to pass the exam because i have passed the exam just with the help of this dumps, so you can do it. -
_q_
 United StatesDo not reply on a dumps to pass the exam.
United StatesDo not reply on a dumps to pass the exam.
Utilize GNS3 or real equipment to learn the technology.
Please do not degrade the value of this Cisco Cert.
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2026 pass2lead.com, All Rights Reserved.