

 Printable PDF
Printable PDF
Databricks Certified Machine Learning Associate: DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Want to pass your Databricks Certified Machine Learning Associate DATABRICKS-MACHINE-LEARNING-ASSOCIATE exam in the very first attempt? Try Pass2lead! It is equally effective for both starters and IT professionals.
- Vendor: Databricks
- Exam Code: DATABRICKS-MACHINE-LEARNING-ASSOCIATE
- Exam Name: Databricks Certified Machine Learning Associate
- Certifications: Databricks Certifications
- Total Questions: 74 Q&As( View Details)
- Updated on: Jul 05, 2026
- Note: Product instant download. Please sign in and click My account to download your product.




- Q&As Identical to the VCE Product
- Windows, Mac, Linux, Mobile Phone
- Printable PDF without Watermark
- Instant Download Access
- Download Free PDF Demo
- Includes 365 Days of Free Updates
VCE
- Q&As Identical to the PDF Product
- Windows Only
- Simulates a Real Exam Environment
- Review Test History and Performance
- Instant Download Access
- Includes 365 Days of Free Updates
Passing Certification Exams Made Easy
Everything you need prepare and quickly pass the tough certification exams the first time
- 99.5% pass rate
- 7 Years experience
- 7000+ IT Exam Q&As
- 70000+ satisfied customers
- 365 days Free Update
- 3 days of preparation before your test
- 100% Safe shopping experience
- 24/7 Support
Databricks DATABRICKS-MACHINE-LEARNING-ASSOCIATE Last Month Results
Related Databricks Certifications Exams
DATABRICKS-MACHINE-LEARNING-ASSOCIATE Online Practice Questions and Answers
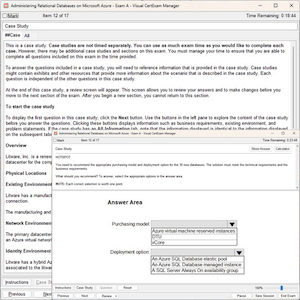
Questions 1
A data scientist has replaced missing values in their feature set with each respective feature variable's median value. A colleague suggests that the data scientist is throwing away valuable information by doing this.
Which of the following approaches can they take to include as much information as possible in the feature set?
A. Impute the missing values using each respective feature variable's mean value instead of the median value
B. Refrain from imputing the missing values in favor of letting the machine learning algorithm determine how to handle them
C. Remove all feature variables that originally contained missing values from the feature set
D. Create a binary feature variable for each feature that contained missing values indicating whether each row's value has been imputed
E. Create a constant feature variable for each feature that contained missing values indicating the percentage of rows from the feature that was originally missing
Questions 2
A machine learning engineer is using the following code block to scale the inference of a single-node model on a Spark DataFrame with one million records:

Assuming the default Spark configuration is in place, which of the following is a benefit of using anIterator?
A. The data will be limited to a single executor preventing the model from being loaded multiple times
B. The model will be limited to a single executor preventing the data from being distributed
C. The model only needs to be loaded once per executor rather than once per batch during the inference process
D. The data will be distributed across multiple executors during the inference process
Questions 3
A data scientist has developed a machine learning pipeline with a static input data set using Spark ML, but the pipeline is taking too long to process. They increase the number of workers in the cluster to get the pipeline to run more efficiently. They notice that the number of rows in the training set after reconfiguring the cluster is different from the number of rows in the training set prior to reconfiguring the cluster.
Which of the following approaches will guarantee a reproducible training and test set for each model?
A. Manually configure the cluster
B. Write out the split data sets to persistent storage
C. Set a speed in the data splitting operation
D. Manually partition the input data
Reviews
-
Mike
 United Statestook the exam yday.passed with almost full mark.Dump is very valid.
United Statestook the exam yday.passed with almost full mark.Dump is very valid. -
Cael
 GreeceGreat dumps ! Thanks a million.
GreeceGreat dumps ! Thanks a million. -
John
 Indiahi guys i had exam yesterday and passed
Indiahi guys i had exam yesterday and passed
It is really a good dumps.Thanks very much. -
Temel
United Statesvalid 100% thanks for helping me pass the exam. -
Kim
 CambodiaI appreciated this dumps not only because it helped me pass the exam, but also because I learned much knowledge and skills. Thanks very much.
CambodiaI appreciated this dumps not only because it helped me pass the exam, but also because I learned much knowledge and skills. Thanks very much. -
zew
 BrazilWonderful. I just passed,good luck to you.
BrazilWonderful. I just passed,good luck to you. -
Osman
 FranceI have tested yet. I prepared my exam only with their materials. Recommend.
FranceI have tested yet. I prepared my exam only with their materials. Recommend. -
Jessie
 EcuadorI just pass the exam with 936. Thanks for helping.
EcuadorI just pass the exam with 936. Thanks for helping. -
Tyrese
 South AfricaPassed yesterday..more than 75% questions came from this dumps.. So happy.
South AfricaPassed yesterday..more than 75% questions came from this dumps.. So happy. -
Nikolai
 YemenGreat dumps! I have passed the exam by using this dumps only half a month. I will share with my friend.
YemenGreat dumps! I have passed the exam by using this dumps only half a month. I will share with my friend.
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2026 pass2lead.com, All Rights Reserved.